面试题39. 数组中出现次数超过一半的数字
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。

思路一:先给数组排序,那么数组中间的数就是“众数”,返回即可。
class Solution {
public:
int majorityElement(vector<int>& nums)
{
sort(nums.begin(),nums.end());
int m=nums.size()/2;
return nums[m];
}
};
时间复杂度是nlogn2,比较慢
思路二:使用hash表。将数组中每个值出现的次数记录进hash表,当发现出现的次数超过数组的一半时,返回数组当前下标的值。
class Solution {
public:
int majorityElement(vector<int>& nums)
{
unordered_map<int,int> mp;
int i;
for(i=0;i<nums.size();i++)
{
mp[nums[i]]++;
if(mp[nums[i]]>nums.size()/2)
break;
}
return nums[i];
}
};
时间和空间复杂度为N
思路三:原地遍历,摩尔投票法。
核心理念为“正负抵消”;时间和空间复杂度分别为N和1;是本题最佳解法。
- 票数和:由于众数出现的次数超过数组长度的一半;若记众数的票数为+1,非众数的票数为-1,则一定有所有数字的票数和>0。
- 票数正负抵消:设数组nums中的众数为x,数组长度为n。若nums的前a个数字的票数和=0,则数组后(n-a)个数字的票数和一定仍是>0(即后(n-a)个数字的众数仍为x)。
下面来看算法流程:












class Solution {
public:
int majorityElement(vector<int>& nums)
{
int votes=0;
int x;
for(int i=0;i<nums.size();++i)
{
if(votes==0)
x=nums[i];
if(nums[i]==x)
votes++;
else
votes--;
}
return x;
}
};
面试题40. 最小的k个数
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。

思路一:先给数组排序,然后输出前k个数即可。时间复杂度为nlog2n。
思路二:用堆。
首先想到的是创建一个小顶堆,把所有元素装进去,然后将k个元素出队。但是这样做效率并不高,时间复杂度也会是nlog2n。
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k)
{
//申请小顶堆
priority_queue<int,vector<int>,greater<int>> q;
for(int i=0;i<arr.size();++i)
q.push(arr[i]);
vector<int> res;
for(int j=0;j<k;++j)
{
res.push_back(q.top());
q.pop();
}
return res;
}
};
那么,我们可以使用大顶堆,堆里只维护k个元素。先将k个元素入堆,后面的元素与堆顶元素比较,如果比堆顶元素小,则堆顶元素出队,该元素入队。
时间复杂度降低为nlog2k。
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k)
{
//申请大顶堆
priority_queue<int> q;
for(int i=0;i<k;i++)//前k个元素入队
q.push(arr[i]);
vector<int> res;
if(k==0) return res; //排除k=0的情况
for(int j=k;j<arr.size();++j)
{
if(arr[j]<q.top())
{
q.pop();
q.push(arr[j]);
}
}
for(int n=0;n<k;++n)
{
res.push_back(q.top());
q.pop();
}
return res;
}
};
思路三:快排变形
“查找第k大的元素”是一类算法问题,称为选择问题。找第k大的数,或者找前k大的数,有一个经典的quick select(快速选择)算法。这个名字和quick sort(快速排序)看起来很像,算法的思想也和快速排序类似,都是分治法的思想。
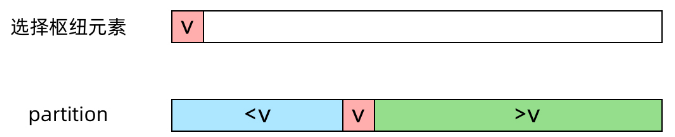
这个partition操作是原地进行的,需要O(n)的时间,接下来,快速排序会递归地排序左右两侧的数组。而快速选择算法的不同之处在于,接下来只需要递归地选择一侧的数组。快速选择算法相当于一个“不完全”的快速排序,因为我们只需要知道最小的k个数是哪些,并不需要知道它们的顺序。
我们的目的是寻找最小的k个数。假设经过一次partition操作,枢纽元素位于下标m,也就是说,左侧的数组有m个元素,是原数组中最小的m个数。那么:
- 若 k = m ,我们就找到了最小的k个数,就是左侧的数组;
- 若 k < m ,则最小的k个数一定都在左侧数组中,我们只需要对左侧数组递归地partition即可;
- 若 k > m ,则左侧数组中的m个数都属于最小的k个数,我们还需要在右侧数组中寻找最小的 k – m 个数,对右侧数组递归地partition即可。
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k)
{
vector<int> res;
if(k==0||arr.empty())
return res;
partition(arr,0,arr.size()-1,k-1);//这里要k-1
for(int i=0;i<k;++i)
{
res.push_back(arr[i]);
}
return res;
}
void partition(vector<int>& arr,int lo,int hi,int k)
{
int m=select(arr,lo,hi);
if(m==k) //前k个数已经找到
return;
else if(m>k) //前k个数在左序列里
partition(arr,lo,m-1,k);
else //前k个数在右序列里
partition(arr,m+1,hi,k);
}
//快速排序找枢纽值下标
int select(vector<int>& arr,int lo,int hi)
{
int j=lo;
int num=arr[lo];
for(int i=lo+1;i<=hi;++i)
{
if(arr[i]<num)
{
swap(arr[j+1],arr[i]);
j++;
}
}
swap(arr[j],arr[lo]);
return j;
}
};
空间复杂度O(1),期望时间复杂度O(n),最坏时时间复杂度O(n^2)。
对于第一次调用partition时,k-1参数的说明:若k的大小恰好是数组元素个数的大小,那么最后一定会调用partition(arr,m+1,hi,k);,因为m永远只会小于k。而在递归后m+1将超出数组下标范围,导致错误,因此第一次调用要k-1。
partition函数中,两次递归调用传入的参数为什么都是k?特别是第二个调用,我们在右侧数组中寻找最小的k-m个数,但是对于整个数组而言,这是最小的k个数。所以说,函数调用传入的参数应该为k。
优先队列和快速选择的比较:
看起来分治法的快速选择算法的时间、空间复杂度都优于使用堆的方法,但是要注意快速选择算法的几点局限性:
- 算法需要修改原数组,如果原数组不能修改的话,还需要拷贝一份数组,空间复杂度就上去了
- 算法需要保存所有的数据。如果把数据看成输入流的话,使用堆的方法是来一个处理一个,不需要保存数据,只需要保存k个元素的最大堆。而快速选择的方法需要先保存下来所有的数据,再运行算法。当数据量非常大的时候,甚至内存都放不下的时候,就麻烦了。所以当数据量大的时候还是用基于堆的方法比较好。
面试题41. 数据流中的中位数
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
void addNum(int num) – 从数据流中添加一个整数到数据结构中。
double findMedian() – 返回目前所有元素的中位数。

思路:使用大顶堆与小顶堆
建立一个 小顶堆A 和 大顶堆B ,各保存列表的一半元素,且规定:
- A 保存 较大 的一半,长度为N/2(N为偶数)或(N+1)/2(N为奇数);
- B 保存 较小 的一半,长度为N/2(N为偶数)或(N-1)/2(N为奇数);
随后,中位数可仅根据 A、B的堆顶元素计算得到。
这里的“较大”与“较小”指的是元素值的大小。
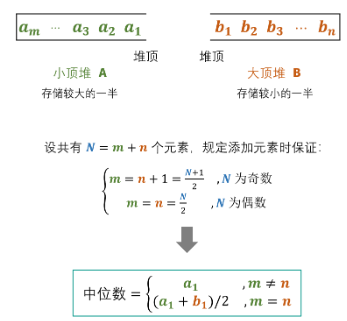
设元素总数为 N = m + n ,其中 m 和 n 分别为 A 和 B 中的元素个数。
为什么要用大顶堆存放较小的一半,小顶堆存放较大的一半呢?
因为该题我们需要访问中位数,两个堆合并起来可以看作排好序的列表,而堆的性质导致我们只能对堆顶元素进行读取,所以我们要把两个堆的堆顶放在一起。
addNum(num) 函数:
- 当 m == n (即N为偶数):需向 A 添加一个元素。实现方法:将新元素 num 插入至 B ,再将 B 堆顶元素插入至 A;
- 当 m ≠ n (即N为奇数):需向 B 添加一个元素。实现方法:将新元素 num 插入至 A ,再将 B 堆顶元素插入至 B;
我们要让两个堆保持平衡,即当N为奇数时,保存较大一半的堆的元素个数比保存较小一半的堆的元素个数多1
findMedian() 函数:
- 当m == n (即N为偶数):则中位数为(A 的堆顶元素 + B 的堆顶元素)/2;
- 当 m ≠ n (即N为奇数):则中位数为 A 的堆顶元素;
复杂度分析:
- 时间复杂度:
- 查找中位数 O(1):获取堆顶元素使用 O(1)时间;
- 添加数字 O(log N):堆的插入和弹出操作使用 O(log N)时间。
- 空间复杂度 O(N):其中 N 为数据流中的元素数量,小顶堆 A 和大顶堆 B 最多同时保存 N 个元素。
class MedianFinder {
public:
/** initialize your data structure here. */
priority_queue<int> min;//大顶堆,用来存值小的一半
priority_queue<int,vector<int>,greater<int>> max;//小顶堆,用来存值大的一半
MedianFinder() {
}
void addNum(int num)
{
//当堆里有奇数个数时,永远是max的数比min多1个
//如果堆里有偶数个数
if(min.size()==max.size())
{
//存放进max
min.push(num);
max.push(min.top());
min.pop();
//不要直接放进max堆,否则可能会导致排序错误(万一num属于min堆呢)
//先放进min堆,排好序后,将队首元素(也就是最大的元素)弹出给max堆,下同
}
else
{
//堆里有奇数个数,存放进min
max.push(num);
min.push(max.top());
max.pop();
}
}
double findMedian()
{
//堆里有偶数个数时,堆顶元素相加除以2
if(min.size()==max.size())
{
return (max.top()+min.top())/2.0;//除数为2.0而不是2,转换为double
}
else
{
//堆里有奇数个数时,中位数为max堆顶元素
return max.top();
}
}
};
面试题42. 连续子数组的最大和
输入一个整型数组,数组里有正数也有负数。数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。

思路:这道题可以用暴力搜索、分治和动态规划来解,其中动态规划是最优解。
动态规划解析:
- 状态定义:设动态规划列表 dp ,dp[i] 代表以元素 nums[i] 为结尾的连续子数组最大和。
- 为何定义最大和 dp[i] 中必须包含元素 nums[i] :保证 dp[i+1] 的正确性;如果不包含 nums[i],递推时则不满足题目的 连续子数组 要求。
- 转移方程:若 dp[i-1] ≤ 0 ,说明 dp[i-1] 对 dp[i] 产生负贡献,
即 dp[i-1] + nums[i] 还不如 nums[i] 本身大。- 当 dp[i-1] > 0 时:执行dp[i] = dp[i-1] + nums[i];
- 当 dp[i-1] ≤ 0 时:执行dp[i] = nums[i];
- 初始状态:dp[0] = nums[0] ,即以 nums[0] 结尾的连续子数组最大和为 nums[0]。
- 返回值:返回 dp 列表中的最大值,代表全局最大值。
用 dp[i] 表示以 nums[i] 结尾的最大和,那么可以得出递推表达式:
dp[i] = max( dp[i-1] + nums[i],nums[i] )
因为如果以 nums[i-1] 结尾的最大和加上 nums[i] 的值小于 nums[i] 的值,那么以 nums[i] 结尾的最大和肯定是 num[i]了。
class Solution {
public:
int maxSubArray(vector<int>& nums)
{
//存放当前dp[i-1]+nums[i]和nums[i]的极大值
vector<int> dp(nums.size(),nums[0]);//先申请size长度的vector,第一个位置要放num[0]
//存放dp数组的最大值
int res=nums[0];
for(int i=1;i<nums.size();++i)
{
dp[i]=max(dp[i-1]+nums[i],nums[i]);
res=max(res,dp[i]);
}
return res;
}
};
一般动态规划空间复杂度是可以进行优化的,我们这个也是可以优化的。
因为我们每次其实只用到了 dp[i-1] 去更新 dp[i] ,那么我们直接使用一个变量去替换就好了。
class Solution {
public:
int maxSubArray(vector<int>& nums)
{
int dp=nums[0];
int res=dp;
for(int i=1;i<nums.size();++i)
{
dp=max(dp+nums[i],nums[i]);
res=max(res,dp);
}
return res;
}
};
面试题43. 1~n整数中1出现的次数
输入一个整数 n ,求1~n这n个整数的十进制表示中1出现的次数。
例如,输入12,1~12这些整数中包含1 的数字有1、10、11和12,1一共出现了5次。

思路:找规律
假设我们对5014这个数字求解。
- 个位上1出现的个数:记高位为high=501,当前位为cur=4
那么高位从0~500变化的过程中,每一个变化中1只出现1次,即(高位1)这样的数字;
高位是501时,因为当前位是4,所以1只能出现一次,即5011;
所以总共出现的次数为high*1+1=502。 - 十位1出现的个数是:记高位high=50,当前位为cur=1,低位为low=4
那么高位从0~49变化的过程中,每一个变化中1出现10次,即(高位10)~(高位19)这样的数字;
高位为50的时候,因为当前位是1,所以我们要看低位来决定出现的次数,因为低位为4,所以此时出现5次,即5010~5014这样的数字;
所以总共出现的次数为high*10+4=504。 - 百位1出现的个数:记高位high=5,当前位cur=0,低位为low=14
那么高位从0~4的过程中,每一个变化1出现100次,即(高位100)~(高位199)这样的数字;
高位为5的时候,因为当前位为0,所以不存在出现1的可能性;
所以总共出现的次数为high*100+0=500。 - 千位1出现的次数:记高位high=0,当前位cur=5,低位low=014
那么因为没有高位所以直接看当前位,因为当前位为5,所以1出现的次数为1000,即1000~1999这样的数字;
所以总共出现的次数为high*1000+1000=1000;
综上最终的结果将每个位置出现的1的次数累加即可。
结论:
我们假设高位为high,当前位为cur,低位为low,i代表着需要统计的位置数(1对应个位,10对应十位,100对应百位)
则对每一位的个数count有:
cur=0,count=high*i;
cur=1,count=high*i+low+1;
cur>1,count=high*i+i;
最终累加所有位置上的个数即最终答案
class Solution {
public:
int countDigitOne(int n)
{
long i=1;//指向遍历的位数i=1指向个位,i=10指向十位……
int count=0;
long high=n/10,cur=n%10,low=0;
while(high !=0 || cur !=0)
{
if(cur==0)
count += high * i;
else if(cur==1)
count += high * i + low + 1;
else
count += high * i + i;
low += cur * i;
cur = high % 10;
high /= 10;
i *= 10;
}
return count;
}
};
面试题44. 数字序列中某一位的数字
数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从下标0开始计数)是5,第13位是1,第19位是4,等等。
请写一个函数,求任意第n位对应的数字。

思路:找规律
我们通过观察,可以发现以下规律:

对于第 n 位对应的数字,我们令这个数字对应的数为 target ,然后分三步进行。
- 首先找到这个数字对应的数是几位数,用 dig 表示;
- 然后确定这个对应的数的数值 target ;
- 最后确定返回值是 target 中的哪个数字。
举个栗子:
比如输入的 n 是 365 :
- 经过第一步计算我们可以得到第365个数字表示的数是三位数,
n = 365 – 9 – 90 × 2 = 176,dig = 3 。这时 n = 176 表示目标数字是三位数中的第176个数字。 - 我们设目标数字所在的数为 number ,计算得到
number = 100 + 176 / 3 =158 ,idx 是目标数字在 number 中的索引,如果 idx = 0 ,表示目标数字是 number 中的最后一个数字。 - 根据上一步骤,我们可以计算得到 idx = n % dig = 176 % 3 = 2,说明目标数字应该是 number = 158 中的第二个数字,即输出为 5 。
class Solution {
public:
int findNthDigit(int n)
{
if(n<=9)
return n;
n-=9;
long long count=90,dig=2;
//计算数位
while(n>count*dig)
{
n-=count*dig;
count*=10;
dig++;
}
//寻找对应的那个数字
long long num=pow(10,dig-1)+n/dig;
//如果刚好这个数字是在最后一位那就是上一个数字的最后一位
//例如n=11,计算出来按道理是11,其实对应的是10的0
if(n%dig==0)
{
num--;
return num%10;
}
else
{
//如果是这个数的第二位,例如7888,那么应该是78/100%10
for(int i=0;i<(dig-n%dig);++i)
num/=10;
return num%10;
}
}
};
面试题45. 把数组排成最小的数
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。

说明:
- 输出结果可能非常大,所以你需要返回一个字符串而不是整数
- 拼接起来的数字可能会有前导0,最后结果不需要去掉前导0
思路:先转换成字符串再组合(排序)
这道题本质上是一道排序题,只是排序规则与常见的升序略有变化。
首先我们要明白的是:无论这些数字怎么取排列,形成的数字的位数是不变的
那么就是高位的数字肯定越小越好。
我们先考虑一下怎么排列两个数字,比如1和20,高位越小越好,放1,组合成120。
我们再看一下三个数的情况,比如36、38和5,首先肯定先放36,剩下38和5,然后对这两个数进行排列,385,所以最后的结果为36385。
由上面的两个例子我们其实就可以知道,放数字的顺序肯定是先放第一位(最左边一位)最小的元素,如果第一位相等,比较第二位……,以此类推。
我们再思考一下,36 < 38 > 5,但是“36”<“38”<“5”。
也就是我们如果把所有数字转换成字符串再排列,刚好就是我们希望的情况。
注意:我们这里说的排列大小比较和字符串大小有点区别,比如3和30,明显30排在前面比较好,所以我们要重构比较,我们组合s1和s2,如果s1+s2 < s2+s1,那么s1 < s2
至此,我们已经分析出来了:
class Solution {
public:
string minNumber(vector<int>& nums)
{
vector<string> str;
string res;
for(int i=0;i<nums.size();++i)
{
str.push_back(to_string(nums[i]));
}
sort(str.begin(),str.end(),cmp);
for(int i=0;i<str.size();++i)
{
res+=str[i];
}
return res;
}
static bool cmp(string &s1,string &s2)
{
return s1+s2<s2+s1;
}
};
面试题46. 把数字翻译成字符串
给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。

思路:动态规划
和青蛙跳台阶的思路很像
跳台阶这道题:跳台阶时每次可以跳一层或两层,求有多少种不同的方法到达终点。
而这道题换成了,每次可以选择一个数字或两个数字,用来合并成一个字符,求可以合成多少种字符串。
这道题的状态转移方程为:

- num[i]和num[i-1]不能合成一个字符,即只能翻译一个数字时,翻译方法的总数不会增加。
- num[i]和num[i-1]能合成一个字符,即既能翻译一个数字,又可以两个数字组合后翻译,那么翻译方法的总数会增加。
那么什么时候只能翻译一个数字呢?
- 当碰到数字‘0’时,不能与后面的数字组合。
- 当组合后数字大于“25”时,超出了字母总数。
class Solution {
public:
int translateNum(int num)
{
string str=to_string(num);
//num最大是2^31,最长不会超过11位
int dp[11];
dp[0]=1;
dp[1]=1;
for(int i=1;i<str.size();++i)
{
//if成立,说明只能翻译1位数字:0开头;大于25的
if(str[i-1]=='0' || str.substr(i-1,2)>"25")
{
dp[i+1]=dp[i];
}
else//可以翻译2位数字
{
dp[i+1]=dp[i]+dp[i-1];
}
}
//数组最后一位是答案
return dp[str.size()];
}
};
面试题47. 礼物的最大价值
在一个 m*n 的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?

思路:动态规划,用DFS的话会超时
设f(i,j)为从棋盘左上角走至单元格(i,j)的礼物最大累计价值,易得到以下递推关系:f(i,j)等于f(i,j-1)和f(i-1,j)中的较大值加上当前单元格礼物价值grid(i,j)
f(i,j)=max[f(i,j-1),f(i-1,j)]+grid(i,j)
因此,可用动态规划解决此问题,以上公式便为转移方程
- 状态定义:设动态规划矩阵dp,dp(i,j)代表从棋盘的左上角开始,到达单元格(i,j)时能拿到礼物的最大累计价值
- 转移方程:
- 当 i = 0 且 j = 0 时,为起始元素
- 当 i = 0 且 j ≠ 0 时,为矩阵第一行元素,只可从左边到达
- 当 i ≠ 0 且 j = 0 时,为矩阵第一列元素,只可从上边到达
- 当 i ≠ 0 且 j ≠ 0 时,可从左边或上边到达
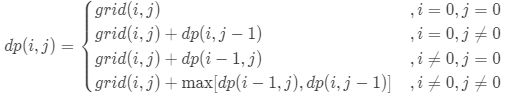
- 初始状态:dp[0][0] = grid[0][0],即到达单元格(0,0)时能拿到礼物的最大累计价值为 grid[0][0]。
- 返回值:dp[row-1][column-1]。
空间复杂度优化:
- 由于 dp[i][j] 只与 dp[i-1][j] ,dp[i][j-1] ,grid[i][j] 有关系,因此可以将原矩阵 grid 用作 dp矩阵,即直接在 grid 上修改即可。
- 应用此方法可省去 dp矩阵 使用的额外空间,因此空间复杂度从MN降至1。
class Solution {
public:
int maxValue(vector<vector<int>>& grid)
{
int row=grid.size();
int column=grid[0].size();
for(int i=0;i<row;++i)
{
for(int j=0;j<column;++j)
{
if(i==0 && j==0)
continue;
else if(i==0)
grid[i][j]+=grid[i][j-1];
else if(j==0)
grid[i][j]+=grid[i-1][j];
else
grid[i][j]+=max(grid[i-1][j],grid[i][j-1]);
}
}
return grid[row-1][column-1];
}
};
注:动态规划直接遍历矩阵,无须考虑矩阵越界问题,这点与DFS不同。
面试题48. 最长不含重复字符的子字符串
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。

思路:滑动窗口(双指针)
题目要求答案必须是字串的长度,意味着字串内的字符在原字符串中一定是连续的。因此我们可以将答案看作原字符串的一个滑动窗口,并维护窗口内不能有重复字符,同时更新窗口的最大值。
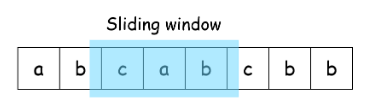
- 初始化头尾指针 head,tail。
- tail指针右移,判断tail指向的元素是否在 [head:tail] 的窗口内。
- 如果窗口中没有该元素,则将该元素加入窗口,同时更新窗口长度最大值,tail指针继续右移。
- 如果窗口中存在该元素,则将head指针右移,直到窗口中不包含该元素
- 返回窗口长度的最大值
时间复杂度为n^2,在判断tail指向的元素是否在窗口内时重复遍历了字符串
所以我们可以用哈希表来优化滑动窗口的时间开销。
使用哈希表记录每个字符的下一个索引,然后尽量向右移动尾指针来扩展窗口,并更新窗口的最大长度。如果尾指针指向的元素重复,则将头指针直接移动到窗口中重复元素的右侧。
- tail指针向末尾方向移动
- 如果尾指针指向的元素存在于哈希表中
- head指针跳跃到重复字符的下一位
- 更新哈希表和窗口长度






class Solution {
public:
int lengthOfLongestSubstring(string s)
{
//0个字符和1个字符时直接返回
if(s.size()<=1)
return s.size();
int head=0,res=0;
unordered_map<char,int> m;
for(int tail=0;tail<s.size();++tail)
{
//查找s[tail],若没找到则返回end()
//若if成立,则表示找到了
if(m.find(s[tail]) != m.end())
head=max(m[s[tail]],head);
//修改字符的映射值为字符索引值+1
m[s[tail]] = tail+1;
//修改滑动窗口的最大长度
res=max(res,tail-head+1);
}
return res;
}
};
对 head=max(m[s[tail]],head); 的解释:
为什么在哈希表中找到重复的字符后不直接移动head指针,而是要和head指针索引比较一下,当字符索引值大于head索引后才移动呢?
因为哈希表里的字符的索引会过期,即索引可能不在滑动窗口内:
像“edabcaedf”这样的字符串,当发现‘a’重复时,头指针要跳到第1个‘a’之后的‘b’,而第1个‘a’之前的‘e’、’d’的下一个索引还保存在哈希表中,且它们的索引在head指针的左侧。当尾指针指向第二个‘a’后面的‘e’时,会认为有重复,而此时‘e’的索引还是1,指向第一个‘d’,若直接更改head指针,那么又改回去了,因此要加个max判断。接着更新‘e’的下一个索引。
面试题49. 丑数
我们把只包含因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。

一个数可以分解成多个因子相乘。
如6可以分解为3*2,3和2就是6的因子;
12可以分解为2*6或3*4,进而再分解为2*2*3。
我们把只包含因子2、3和5的数称为“丑数”。
特殊:1是丑数。
这道题让我们按从小到大的顺序输出第n个丑数
思路:
- 丑数可以分解为2、3、5因子,因此我们可以反过来用2、3、5来构造丑数。
- 申请 数组dp ,dp数组按从小到大的顺序存放丑数,第一位 dp[0]=1。
- 申请三个指针 p2 、 p3 和 p5 ,p2指向的数字永远乘2,p3指向的数字永远乘3,p5指向的数字永远乘5。
- 因为是升序存放,我们从 dp[p2]*2 、 dp[p3]*3 和 dp[p5]*5 中选取一个最小的数,即新丑数,放进dp尾部;然后将被选取的指针向后移动一位。
- 接着循环执行上一步,循环n-1次。
- 最后返回dp数组最后一位。
这个方法与合并多个排序数组的方法类似:每个数组一个指针,从左往右比较三个指针指向数字的大小,将最小的放入新数组,并将指针后移一位;若遇到相同数字 ,则只添加一个数字进新数组,并且相同数字的指针都要后移一位。不同的是,本体中我们需要将数字乘上2、3或者5后再进行比较。
class Solution {
public:
int nthUglyNumber(int n)
{
vector<int> dp(n,0);
dp[0]=1;
int p2=0,p3=0,p5=0;
for(int i=1;i<n;++i)
{
//取三个指针指向的数乘因子后的最小数
dp[i]=min(dp[p2]*2,min(dp[p3]*3,dp[p5]*5));
//将取到的数的指针向后移一位
if(dp[i]==dp[p2]*2) ++p2;
if(dp[i]==dp[p3]*3) ++p3;
if(dp[i]==dp[p5]*5) ++p5;
}
return dp[n-1];
}
};
面试题50. 第一个只出现一次的字符
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。

思路一:哈希表
字符作为key,字符出现的次数作为value构造哈希表。
然后逐个字符扫描字符串s,若该字符的value为1,则返回它。
class Solution {
public:
char firstUniqChar(string s)
{
unordered_map<char,int> mp;
for(char c:s)
++mp[c];
for(char c:s)
if(mp[c]==1)
return c;
return ' ';
}
};
思路二:数组
class Solution {
public:
char firstUniqChar(string s)
{
//26个字母一个字母一个坑
vector<int> v(26);
for(char ch:s)
v[ch-'a']++;
for(int i=0;i<s.size();++i)
{
if(v[s[i]-'a']==1)
return s[i];
}
return ' ';
}
};
这道题用数组比哈希表更快,但扩展性不太好,若字符范围扩大,则需要改写方法。
面试题52. 两个链表的第一个公共节点
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
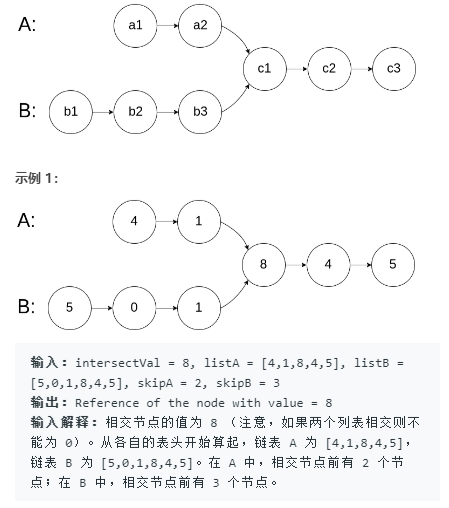
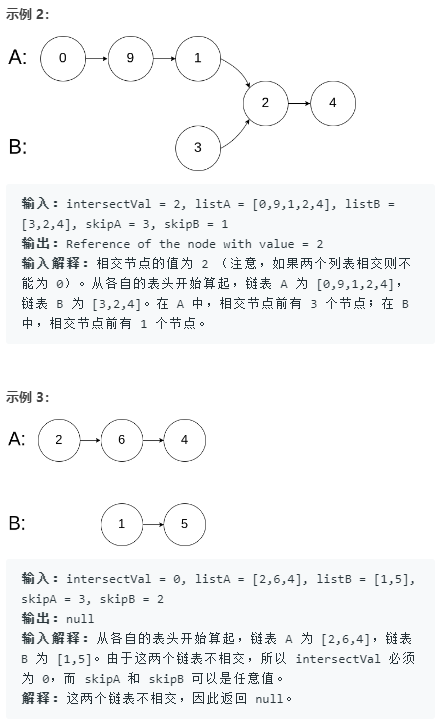
注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
思路:双指针
- 两个指针node1、node2分别指向两个链表的头结点headA和headB。
两指针同时向后遍历; - 当node1指向链表末尾的null时,跳转到headB,然后继续遍历;
- 当node2指向链表末尾的null时,跳转到headA,然后继续遍历;
- 如果两个链表有公共节点,则(在第二次遍历中)当两指针相等时,就指向了公共节点;
- 如果两个链表没有公共节点,当两指针(在第二次遍历的最后)都指向null时,代表两个链表没有公共节点。









class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB)
{
ListNode *node1 = headA;
ListNode *node2 = headB;
while(node1 != node2)
{
if(node1 != nullptr)
node1 = node1->next;
else
node1 = headB;
if(node2 != nullptr)
node2 = node2->next;
else
node2 = headA;
}
return node1;
}
};
顺便贴一个用哈希表的代码:
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB)
{
ListNode *node1 = headA;
ListNode *node2 = headB;
unordered_map<ListNode *,int> mp;
while(node1 != nullptr || node2 != nullptr)
{
if(node1 != nullptr)
{
if(mp.find(node1) != mp.end())
return node1;
mp[node1] = node1->val;
node1 = node1->next;
}
if(node2 != nullptr)
{
if(mp.find(node2) != mp.end())
return node2;
mp[node2] = node2->val;
node2 = node2->next;
}
}
return NULL;
}
};